Phase 1: Comprehension
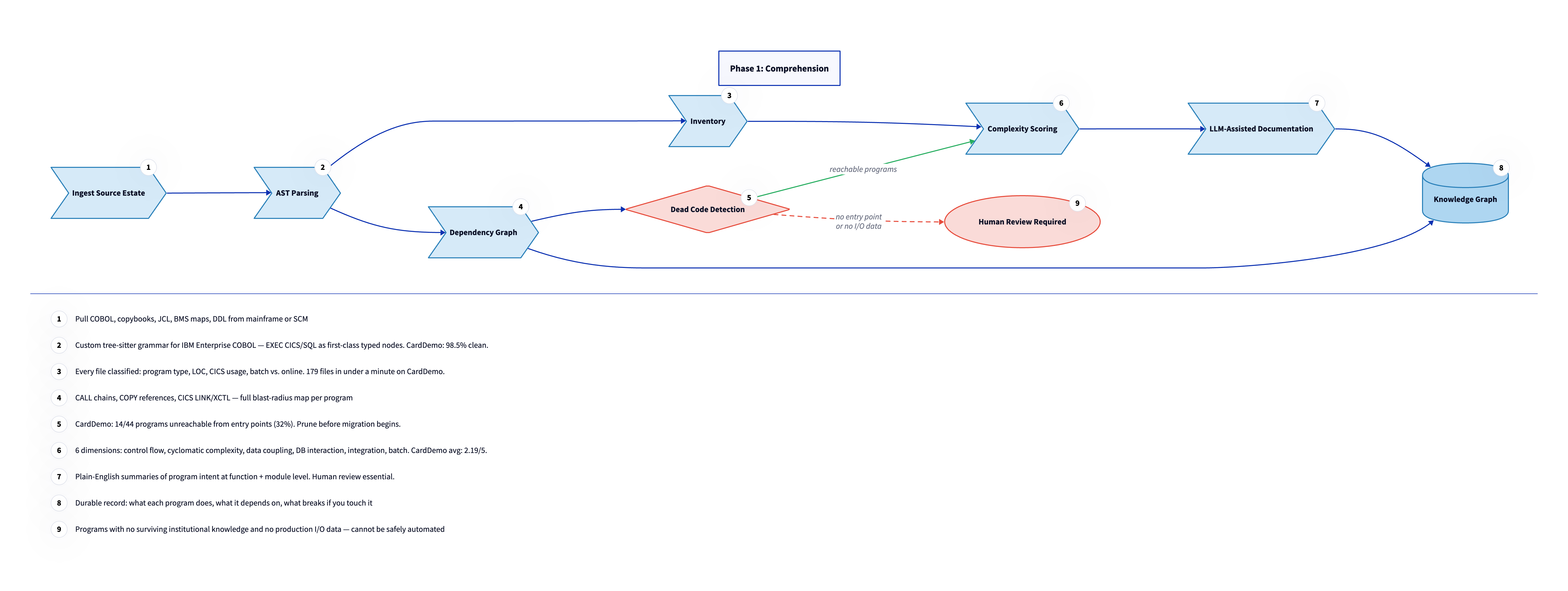
The bottleneck in mainframe modernization is not compute power or tooling. It is institutional knowledge. Most COBOL estates have been running for 30 to 50 years, and the engineers who wrote the original code are retired or gone. What remains is a body of behavior encoded in programs that nobody fully understands anymore. Before any migration work can begin, that knowledge has to be reconstructed from the source itself. Phase 1 builds that reconstruction systematically. Every program in the estate is parsed, classified, analyzed for dependencies, scored for complexity, and documented in plain English. The output is a knowledge graph: a structured, queryable picture of the estate that makes it possible to plan migration work with real data instead of estimates based on line counts and gut feel. Nothing in Phase 2 starts until Phase 1 is complete.
Mainframe source control. Mainframe source control varies by shop. The most widely deployed system is CA Endevor (Broadcom). Others include ChangeMan ZMF (Serena/Broadcom), Panvalet (Broadcom), and Librarian. They predate Git and store source as fixed-width members on the mainframe. There is no native integration with modern version control; extraction requires a bulk export step before any analysis can begin.
Ingest the source estate
The estate typically includes COBOL programs (.cbl, .cob), copybooks (.cpy), JCL jobs (.jcl), BMS screen maps (.bms), DB2 DDL, and flat file definitions. Source is pulled from either the mainframe itself via FTP or SFTP, or from the shop's source control system (CA Endevor, ChangeMan ZMF, Panvalet, Librarian, or equivalent). Extraction requires a bulk export from each. There is no Git integration, no incremental pull, and no change history in a format that modern tooling can consume. Three common pitfalls arise at this stage. First, mainframe source is stored in EBCDIC encoding and must be converted to ASCII or UTF-8 before any text-based tooling can process it. Second, source members use fixed-width 80-column records, which means trailing spaces are significant and some tools mangle them on conversion. Third, mainframe source libraries often contain non-source artifacts mixed in with code members: load module listings, run statistics, and other metadata that must be filtered out before parsing begins.
AST (Abstract Syntax Tree). A structured representation of source code produced by a parser. Where raw source is text, an AST is a queryable data structure: it captures what functions exist, what they call, what data they define, and how control flows through the program. The analysis pipeline operates on the AST, not on raw source text.
EXEC CICS / EXEC SQL. Embedded command blocks in COBOL programs that invoke CICS transactions or database operations. They are syntactically distinct from standard COBOL and require special handling by parsers. Most open-source COBOL parsers treat them as unstructured text, which makes the resulting parse tree useless for any analysis that cares about what the program actually does.
Parse every file
Most open-source COBOL parsers fail on real-world enterprise COBOL because they treat EXEC CICS and EXEC SQL blocks as opaque text, producing ERROR nodes in the parse tree. This is acceptable for syntax highlighting but fatal for dependency analysis: if CICS commands are unparsed blobs, you cannot extract what files they read, what programs they call, or what response codes they check. We built a tree-sitter grammar specifically for IBM Enterprise COBOL that parses these blocks as typed AST nodes with named fields. A CICS READ command produces a node with a DATASET field, an INTO field, a RIDFLD field, and an optional RESP field. That structure is what makes it possible to trace data flow and build accurate dependency graphs. The grammar is available as tree-sitter-cobol-enterprise on GitHub. Validation against the AWS CardDemo corpus shows 65 of 66 programs parsing cleanly, a 98.5% success rate. The existing npm tree-sitter-cobol package produces ERROR nodes on 25 of those same 44 COBOL programs containing CICS commands.
Build the inventory
Every file in the estate is classified and measured. The inventory captures file type (COBOL program, copybook, JCL job, BMS screen map, Assembler), subtype (CICS online versus batch), lines of code, CICS command count, GO TO count, and CALL count. These metrics are not decorative: they feed directly into the complexity scoring and wave planning steps that follow. The inventory runs against the full estate in under a minute for a corpus the size of CardDemo, which contains 179 files. The output is a structured JSON inventory that every downstream analysis step reads as input — see the CardDemo inventory for a real example. This makes the pipeline reproducible: rerun it after any change to the source, and the inventory updates automatically.
Copybook. A reusable file containing COBOL data definitions, analogous to a shared type definition or header file in modern languages. Programs import copybooks using COPY directives. Understanding which copybooks are shared across programs is critical: changing a copybook affects every program that uses it.
Build the dependency graph
The dependency graph traces every CALL chain, COPY reference, CICS LINK, and CICS XCTL across the estate. Each node is a program or copybook; each edge is a typed dependency with direction. This graph is what makes migration sequencing possible. You cannot migrate a program until everything it depends on is already migrated and running in the target environment. The graph also surfaces the blast radius of any given change: if you modify a copybook, every program that COPYs it is potentially affected. CardDemo analysis produced a graph of 44 programs and 30 copybooks, with the full call graph including CICS transaction references — see the dependency graph which renders directly in GitHub. In a real enterprise estate, this graph often reveals program relationships that the client's own team was not aware of because the knowledge was never written down.
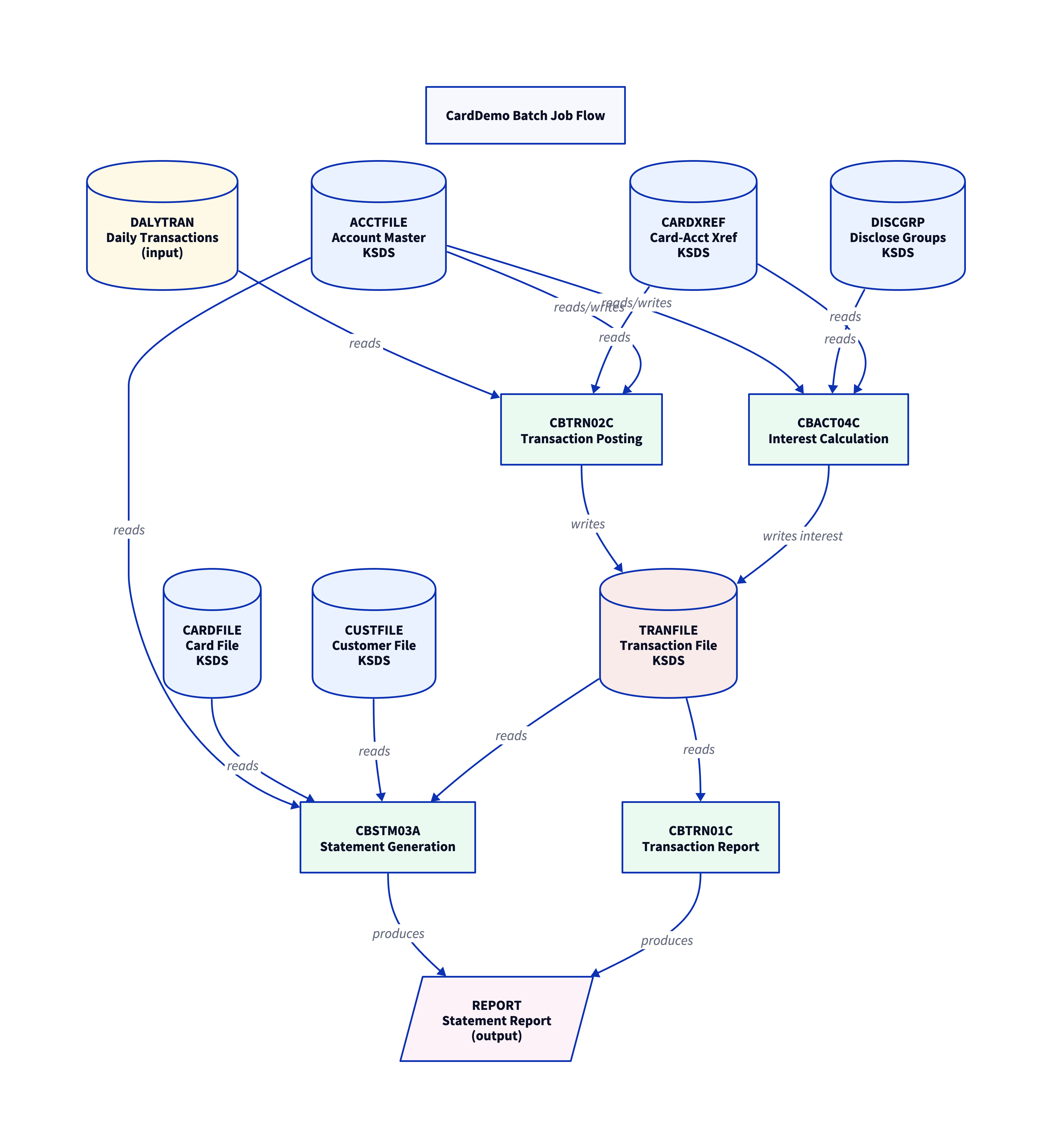
The same comprehension pass also produces a batch job flow diagram, tracing how nightly JCL jobs read and update VSAM masters across the daily transaction posting and statement generation pipelines. This view is what makes batch dependencies visible alongside the online program graph above; both are needed before wave sequencing in Phase 2.
Detect dead code
Dead programs are those that are unreachable from any entry point in the dependency graph. No JCL job invokes them, no program CALLs them, no CICS transaction references them. They exist in the library but serve no function in production. In CardDemo, 14 of 44 programs are unreachable, a dead code rate of 32%. Dead paragraphs, which are unreachable sections within otherwise reachable programs, add another 33 to the count. This rate is consistently higher than client teams expect. Dead code is not migrated. Removing it from scope before translation begins reduces the estimated work by roughly a third in a typical estate, which is significant enough to change the business case for migration. The CardDemo corpus produced a dead code analysis identifying all unreachable programs and paragraphs.
Score complexity
Cyclomatic complexity. A count of the number of independent execution paths through a program. A program with no branching has a cyclomatic complexity of 1. Every IF, PERFORM UNTIL, EVALUATE WHEN, and GO TO adds 1. A score above 10 is generally considered hard to test; scores above 50 indicate programs that are difficult to reason about in any language. It is one of the six dimensions in our composite complexity score, and often the strongest predictor of how long a program will take to migrate correctly.
Each program is scored across six dimensions: control flow complexity, cyclomatic complexity, data coupling, database interaction, integration surface, and batch complexity. The composite score runs from 0 to 5. Programs above 3.5 are flagged for human specialist review before any automated translation is attempted. CardDemo averages 2.19 across 44 programs. Three programs scored above 3.5 — see the full complexity scores. The hardest program is COACTUPC at 4.1: 3,368 lines, 17 CICS commands, and 51 GO TO statements. That program cannot be safely automated. It requires a human who understands both the COBOL control flow and the business logic it implements to produce a correct TypeScript equivalent.
LLM (Large Language Model). A class of AI model trained on large text corpora that can generate, summarize, and reason about natural language and code. In this pipeline, LLMs generate plain-English descriptions of what each program does, based on its AST and inventory data. Human review is required before those descriptions are treated as authoritative.
Generate LLM-assisted documentation
Once the AST and inventory are in place, LLMs generate plain-English summaries of each program at the function and module level. The input to the LLM is the structured AST, not raw COBOL text. This distinction matters: reasoning from the AST means the LLM is working with the program's actual structure, not inferring it from indentation and naming conventions. The output is a natural language description of what each program does, what it reads and writes, what it calls, and what would break if it changed. Human review is required before any of these summaries are treated as authoritative. LLMs can misread complex control flow, miss implicit state dependencies, and confidently describe behavior that is subtly wrong. For programs with complex business rules, the summaries are a starting point for human review, not a replacement for it.
The output: knowledge graph
The knowledge graph is the deliverable from Phase 1. It is a structured, queryable record of the estate: what each program does, what it depends on, what breaks if you touch it, and how complex it is. Every program has a node. Every dependency has a typed edge. Every node has complexity scores and a plain-English summary attached. This graph is the foundation for the wave plan in Phase 2. It is also what gets handed to the client team as documentation. For most clients, it is the first comprehensive picture of their own estate that anyone has had in years. Some clients have used it independently of the migration project, as a reference for onboarding new engineers or auditing the estate before making infrastructure changes.
For a concrete example, see the CardDemo executive summary — the non-technical artifact produced at the end of Phase 1 for a real COBOL corpus. The data model shows how VSAM file structures map to relational schemas. The credential scan shows what a security pass finds in existing production code.
Human review flag
Some programs exit Phase 1 with a flag that blocks them from entering Phase 2 automatically. These are programs where no surviving institutional knowledge exists and no production I/O data is available. Without I/O data, there is no way to generate a regression test suite. Without a regression test suite, there is no way to validate translation. Automated migration of these programs is not safe. Flagged programs require manual specification work before Phase 2 begins. This means interviewing any remaining domain experts, reviewing any printed documentation, and reverse-engineering expected behavior from production logs or downstream system behavior. The amount of work this takes varies widely depending on how long the program has been running and how well it was originally documented. In some cases it is a day of investigation. In others it is weeks. Either way, it must happen before translation starts.