Phase 2: Planning
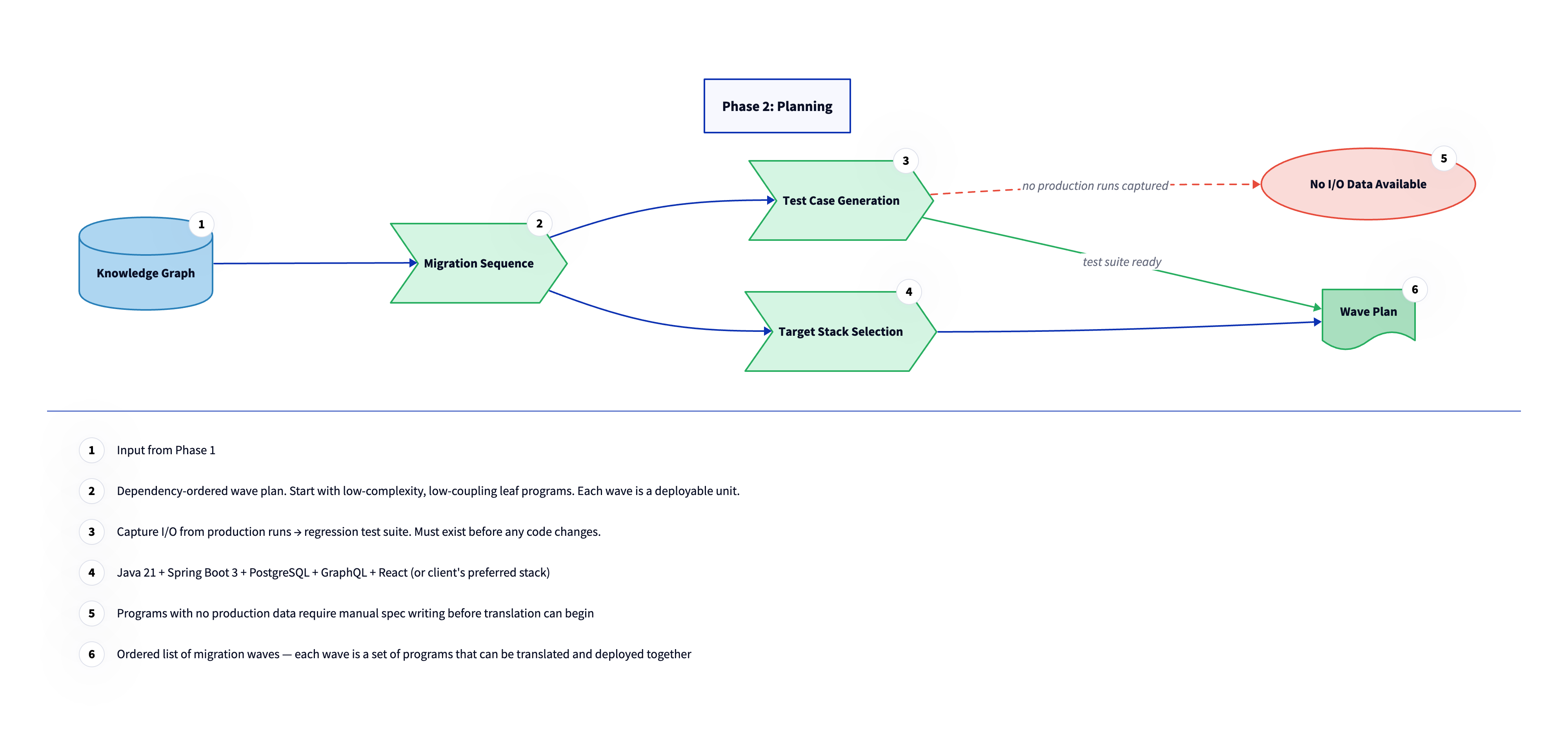
Phase 2 turns the knowledge graph into an executable plan. Three things happen here in sequence: the migration order is determined, the regression test infrastructure is built, and the target stack is confirmed. These are not parallel tracks. Each one depends on the output of the one before it, and nothing in Phase 3 starts until all three are done. The knowledge graph from Phase 1 contains everything needed to make these decisions with real data. Wave sequencing is derived from the dependency graph. Test coverage is driven by the program inventory. Stack selection is informed by the complexity scores and the integration surface analysis. Phase 2 is where that data gets turned into commitments.
Dependency graph. A directed graph where each node is a program or data artifact and each edge represents a dependency between them. A program that calls another program has an outgoing edge to that program. The graph determines migration order: a program cannot be migrated until everything it depends on has already been migrated. It also surfaces the blast radius of any change.
Build the wave plan
The wave plan sequences migration work into discrete, deployable batches called waves. Each wave is a set of programs that can be translated and deployed together because their upstream dependencies are already running in the target environment. A program cannot enter a wave until every program it depends on has already shipped. The sequencing algorithm starts from leaf programs, those with no outgoing dependencies, and works inward toward the programs with the most business-critical logic and the most dependents. Programs are assigned to waves based on their depth in the dependency graph and their complexity scores. Low-complexity, low-coupling programs go first; high-complexity, high-coupling programs go last.
This ordering is deliberate: early waves are learning exercises. By the time the hardest programs are reached in later waves, the team has built translation patterns, tooling, and confidence on programs where mistakes are cheaper to fix.
In the CardDemo spike, this produced an 8-wave migration sequence with simple batch readers first and complex CICS financial transactions last.
Capture regression test data
Before any code changes are made, production runs of each program are instrumented to capture input/output pairs. These pairs become the regression test suite that validates translation in Phase 3. The principle is simple: if the translated program produces the same outputs as the mainframe program for the same inputs, the translation is correct. No translation work starts on a program until that test suite exists. For programs where no production data is available, whether because they handle edge cases that rarely fire or because they have not been run in years, manual specification work is required first. This is the same situation flagged at the end of Phase 1 for programs with no institutional knowledge. The test data capture step and the human review flag are two sides of the same problem: programs that are invisible to production instrumentation are also the programs whose behavior is hardest to verify after translation.
TypeORM. A TypeScript-native ORM (Object-Relational Mapper) that maps database tables to TypeScript classes and handles queries through a typed API. In this migration, COBOL copybook structures and ADABAS file definitions become TypeORM entities, and database access verbs (READ, FIND, STORE) become TypeORM repository methods.
Confirm the target stack
The target stack is confirmed in Phase 2, not assumed. The right answer is not the best technology in the abstract. It is the technology that the client's engineering team already builds and maintains, so that the migrated code can be owned by people who know the stack without needing a migration specialist to explain it.
The migration adapts to the client's existing stack, not the other way around. Common patterns include TypeScript on Node.js (Express, Fastify, NestJS, or equivalent), Java with Spring, Python with Django or FastAPI, and Go. There is no universally correct choice; the right one is whatever the receiving engineering organization already supports in production with mature deployment pipelines, monitoring, and on-call coverage. The best possible outcome is for migrated code to land in an environment the team already understands, alongside deployment pipelines and observability that already exist. When a client has an established platform for new application development, that platform is almost always the right target.
For a concrete example, the CardDemo spike technology decisions document explains how we selected TypeScript/NestJS for that particular corpus and what trade-offs it involved. The risk matrix and POC plan show how the first wave was scoped and de-risked.